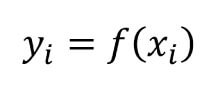
مرتب کردن اغلب حس خوبی به ما میدهد. مثلاً مرتب کردن اتاق و قرار دادن هرچیزی سر جایش. شاید بعضی از ما ابتدا کمی نسبت به مرتب کردن گارد داشته باشیم. اما بعد از مرتب شدن وسایلمان، احساس بسیار خوبی را تجربه میکنیم. گاهی اوقات ممکن است حجم وسایلی که باید مرتب شوند، خیلی زیاد باشد. در چنین مواقعی ممکن است آرزو کنیم کاش میشد یک کمد یا قفسه هوشمند ساخته میشد تا ما تمام وسایل را در آن میریختیم و کمد خودش وسایل را دستهبندی و مرتب میکرد.
چنین کمد جادویی برای این که بتواند کار کند، نیاز دارد تا ابتدا یک سری ویژگیهایی را که میخواهیم وسایل را بر اساس این ویژگیها دستهبندی کند برایش تعریف کرد. برای مثال رنگ، سایز، جنس و…
حالا همین سناریو را تعمیم دهیم به دادهها. در ماشین لرنینگ هم الگوریتمهای مختلفی تحت عنوان الگوریتمهای طبقهبندی (Classification algorithms) وجود دارند که در این مقاله به معرفی این الگوریتمها خواهیم پرداخت.
Classification چیست؟
Classification فرآیند شناسایی، درک و دسته بندی دادهها یا اشیای از پیش تعیین شده است. الگوریتم طبقه بندی یک تکنیک یادگیری نظارت شده است. در این تکنیک، ماشین از مجموعهای از دادهها یاد میگیرد و سپس آنها را به تعدادی کلاس یا گروه طبقهبندی می کند. مانند، بله یا خیر، 0 یا 1، هرزنامه یا عدم هرزنامه، گربه یا سگ، و غیره. از آنجایی که الگوریتم طبقه بندی یک تکنیک یادگیری نظارت شده است، بنابراین دادههای ورودی باید برچسبگذاری شده باشند.
اگر با انواع روشها در ماشین لرنینگ آشنایی ندارید، پیشنهاد میکنم حتما مقاله مقالههای زیر را مطالعه کنید.
انواع یادگیری ماشین همراه با مثال
یادگیری نظارت شده در ماشین لرنینگ (راهنمای جامع)
یادگیری نظارت نشده در ماشین لرنینگ(راهنمای جامع)
به طور خلاصه در روش نظارت شده، از توابعی استفاده می شود که بتواند یک برچسب از قبل تعریف شده را برای مجموعهای از ورودیها پیشبینی کند. در حالیکه در یادگیری بدون نظارت، یک الگوی خاص در مجموعهای از دادهها وجود دارد که باید کشف شود.
طبقهبندی و رگرسیون
یادگیری نظارت شده را میتوان به دو دسته طبقهبندی و رگرسیون دستهبندی کرد. روش طبقهبندی که روش مورد نظر ما در این مقاله است، روشی است که مشخص میکند یک شیء خاص متعلق به چه دسته یا گروهی است. در حالیکه در روش رگرسیون، همین فرآیند برای دادههای پیوسته مشخص میشود. مرز باریکی میان الگوریتمهایی که برای این دو روش استفاده میشود، وجود دارد. در واقع ممکن است بعضی از این الگوریتمها برای هر دو روش قابل استفاده باشد.
در این مقاله به بررسی ۶ الگوریتم طبقهبندی ماشین لرنینگ خواهیم پرداخت.
کاربرد الگوریتمهای پیادهسازی
الگوریتمهای طبقهبندی را میتوان در مکانهای مختلف مورد استفاده قرار داد. در زیر چند مورد استفاده از الگوریتمهای طبقهبندی آورده شده است:
- تشخیص هرزنامه ایمیل
- تشخیص گفتار
- شناسایی سلول های تومور سرطانی
- طبقه بندی داروها
- شناسایی بیومتریک و غیره
بیشتر بخوانید: “معرفی روش های یادگیری و الگوریتم های ماشین لرنینگ“
الگوریتمهای طبقهبندی چگونه کار میکنند؟
برای حل مسایل طبقهبندی در ماشین لرنینگ، از مدلهای ریاضی استفاده میشود که وظیفهشان این است که ارتباط میان یک متغیر خاص مانند x به مقادیر متغیر خروجی مانند y را بیایند. به عبارت دیگر تابع، خروجی را بر اساس ویژگیهای متغیر ورودی پیشبینی می کند.

پردازش داده
قبل از اینکه هر الگوریتم آماری را در مجموعه داده خود اعمال کنیم، باید متغیرهای ورودی و متغیرهای خروجی را کاملاً درک کنیم. در مسائل طبقهبندی، هدف همیشه کیفی است، اما گاهی اوقات، حتی مقادیر ورودی نیز میتواند طبقهبندی شود، به عنوان مثال، جنسیت مشتریان در مجموعه دادههای مشتریان یک مرکز خرید. از آنجایی که الگوریتمهای طبقهبندی بر اساس مدلهای ریاضی هستند، باید همه متغیرهای آنها را به مقادیر عددی تبدیل کرد. در نتیجه اولین گام در کار یک الگوریتم طبقهبندی این است که اطمینان حاصل شود که متغیرها، اعم از ورودی و خروجی، به درستی کدگذاری شدهاند.
ایجاد مجموعه دادههای تست و آموزش
پس از پردازش مجموعه دادهها، نوبت تقسیم دادهها به دو بخش مجموعه داده آزمایشی و مجموعه داده آموزشی است. به کمک دادههای آموزشی، ماشین الگوی بین مقادیر ورودی و خروجی را یاد میگیرد و سپس با مجموعه داده آزمایشی این مرحله اجازه می دهد تا از مجموعه داده آموزشی استفاده کنیم تا ماشین ما الگوی بین مقادیر ورودی و خروجی را یاد بگیرد. از سوی دیگر، یک مجموعه داده آزمایشی، دقت مدل را آزمایش میکند که ما سعی خواهیم کرد آن را در مجموعه دادههای خود قرار دهیم.
انتخاب مدل
هنگامی که مجموعه داده را به آموزش و آزمایش تقسیم کردیم، وظیفه بعدی انتخاب مدلی است که به بهترین وجه با مسئله ما مطابقت دارد. برای این کار، باید از الگوریتمهای طبقهبندی آگاه باشیم تا بتوانیم بهترین الگوریتم را با توجه به دادههای خود انتخاب کنیم.
بنابراین، اجازه دهید به مجموعه ای از انواع مختلف الگوریتم های طبقه بندی شیرجه بزنیم و گزینه های خود را بررسی کنیم.
Logistic Regression
الگوریتم رگرسیون لجستیک یک الگوریتم پایه و در عین حال مهم در یادگیری ماشین است که از یک یا چند متغیر مستقل برای تعیین نتیجه استفاده می کند. رگرسیون لجستیک سعی میکند بهترین رابطه را بین متغیر وابسته و مجموعهای از متغیرهای مستقل پیدا کند. این الگوریتم از تابع سیگموئید استفاده میکند. از این الگوریتم در مواقعی که دستهبندی دوگانه داریم، استفاده می شود. برای مثال درست و نادرست، مثبت و منفی و…

Decision Tree
درخت تصمیم شاخههای درخت را در یک رویکرد سلسله مراتبی میسازد که هر شاخه را میتوان به عنوان یک عبارت if-else در نظر گرفت. شاخهها با تقسیم مجموعه داده به زیرمجموعههایی بر اساس مهمترین ویژگیها توسعه مییابند. طبقهبندی نهایی در لایه آخر برگ درخت تصمیم اتفاق میافتد.

Random forest
الگوریتم جنگل تصادفی همانطور که از نامش پیداست، مجموعهای از درخت تصمیم است. هر درخت مقداری را برای احتمال متغیرهای هدف پیشبینی میکند. میانگین این مقادیر به عنوان خروجی نهایی تابع بازگردانده میشود.

Support Vector Machine (SVM)
مفهوم اصلی ماشین بردار پشتیبان و نحوه عملکرد آن را می توان با این مثال ساده به بهترین شکل درک کرد. فرض کنید مجموعه دادهای دارید که شامل دو برچسب آبی و سبز هستند. شما میخواهید این دادهها را با توجه به همین برچسبها، بر اساس ویژگی x و y دستهبندی کنید. (ویژگی x و y میتواند هرچیزی باشد.) در نتیجه به ازای هر مختصات (x,y) خروجی یک برچسب آبی یا سبز خواهد بود. الگوریتم ماشین بردار پشتیبان به این صورت کار میکند که دادهها را روی یک صفحه رسم میکند. مرزهای متعددی را میتوان میان دو برچسب مختلف رسم کرد. اما الگوریتم SVM سعی میکند خطی را به عنوان مرز انتخاب کند که بیشترین فاصله را با نزدیکترین داده از هر برچسب داشته باشد.
در صورتیکه یک خط راست نتواند به خوبی دادهها را دستهبندی کند، نیاز است تا دادهها را به فضای سه بعدی منتقل کنیم.

K-Nearest Neighbor (KNN)
برای توضیح این الگوریتم اجازه دهید از مثال استفاده کنم. نمودار زیر را در نظر بگیرید. این نمودار شامل نقاط سبز و زرد است. فرض کنید میخواهیم بدانیم نقطهای مانند نقطهای که در شکل زیر مشخص شده، متعلق به کدام دسته یا کلاس است. برای این کار این الگوریتم، فاصله ایت تقطه را با نزدیکترین نقاط همسایه محاسبه میکند و بر اساس میزان فاصله، مشخص میکند این نقطه متعلق به چه دستهایست.

Naïve Bayes
الگوریتم Naïve Bayes یا بیز ساده، بر اساس قضیه بیز است. طبق این قضیه، الگوریتم بیز فرض میکند که هر ویژگی از دادهها مستقل از ویژگیهای دیگر است. یکی از مزایای اصلی این الگوریتم این است که برخلاف سایر الگوریتمهای طبقهبندی در ماشین لرنینگ که به حجم عظیم داده نیاز دارند، این الگوریتم میتواند با داده کم نیز کار کند.

چگونه بهترین الگوریتم طبقهبندی را انتخاب کنیم؟
در این بخش لیستی داریم که به شما کمک میکند بفهمید از کدام الگوریتمهای طبقهبندی ماشین لرنینگ باید برای حل مشکل استفاده کنید.
اندازه مجموعه داده: اندازه مجموعه داده پارامتری است که هنگام انتخاب یک الگوریتم باید در نظر بگیرید. اگر اندازه مجموعه داده کوچک است، میتوانید از الگوریتمهای بایاس کم و واریانس بالا مانند Naïve Bayes استفاده کنید. در مقابل، اگر مجموعه داده بزرگ باشد، تعداد ویژگیها زیاد است، باید از الگوریتمهای بایاس بالا و واریانس کم مانند KNN، درخت تصمیم و SVM استفاده کنید.
دقت پیش بینی: دقت یک مدل، پارامتری است که میزان خوب بودن یک الگوریتم طبقهبندی را ارزیابی میکند. این نشان میدهد که مقدار خروجی پیشبینی شده چقدر با مقدار خروجی صحیح مطابقت دارد.
زمان آموزش: گاهی اوقات، الگوریتمهای ماشین لرنینگ پیچیده مانند SVM و Random Forests ممکن است زمان زیادی را برای محاسبه صرف کنند. در کنار این، مجموعه دادههای بزرگ نیز به هر حال به زمان بیشتری برای یادگیری الگو نیاز دارند. در چنین شرایطی پیادهسازی الگوریتمهای ساده مانند رگرسیون لجستیک آسانتر است و در زمان صرفهجویی میشود.
تعداد ویژگیها: گاهی اوقات، مجموعه داده ممکن است به طور غیر ضروری دارای ویژگیهای زیادی باشد و همه آنها مرتبط نباشند. در این حالت استفاده از الگوریتمهایی مانند SVM برای چنین مواردی مناسبتر است.
کلام آخر
در این مقاله از آمانج به بررسی الگوریتمهای طبقهبندی در ماشین لرنینگ پرداختیم. الگوریتمهایی که در این مقاله به آنها پرداخته شد، معروفترین الگوریتمهای طبقه بندی در ماشین لرنینگ هستند اما این بدان معنا نیست که تنها الگوریتمهای classification هستند. همانطور که میدانید در ماشین لرنینگ با حجم عظیمی از داده سروکار داریم. دستهبندی این دادهها و طبقهبندی آنها کاریست که به صورت دستی غیر قابل انجام است. در نتیجه باید برای این کار به الگوریتمهای طبقهبندی در ماشین لرنینگ پناه بیاوریم.
پس اگر به قدرت ماشین لرنینگ در آینده ایمان آوردهاید و تصمیم دارید فعالیتتان را افزایش دهید، بهتر است از راه درستش اقدام کنید. اولین قدم برای یادگیری ماشین لرنینگ، شرکت در دوره آموزش پایتون پروژهمحور است. پس از یادگیری برنامهنویسی پایتون نوبت به یادگیری ماشین لرنینگ میرسد. برای یادگیری ماشین لرنینگ ابتدا نیاز به یادگیری ریاضیات پایه ماشین لرنینگ دارید. الگوریتمهای ماشین لرنینگ نیز بر پایه همین ریاضیات، طراحی شدهاند که در دوره آموزش ماشین لرنینگ به صورت کامل به آن پرداخته خواهد شد.
برای تهیه این مقاله از منابع زیر استفاده شده است:
towardsdatascience.com
analyticsvidhya.com
The post الگوریتم طبقهبندی، هسته اصلی ماشین لرنینگ appeared first on آمانج آکادمی مرکز آموزش های برنامه نویسی ، دیجیتال مارکتینگ و دیزاین.